A lot has been happening with the peermaps project. This is our first update summarizing what we've been up to.
Back in January 2019, we received a $50k USD grant from samsung to accelerate our work on peermaps.
In May, substack gave a talk at DTN. You can read the slides here:
https://github.com/substack/dtn-2019-peermaps-slides
The talk was recorded and the video should be up sometime soon.
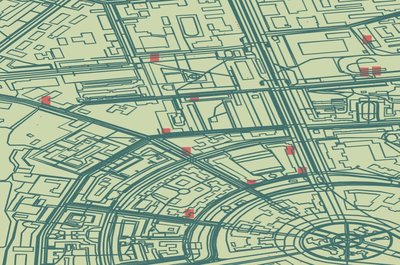
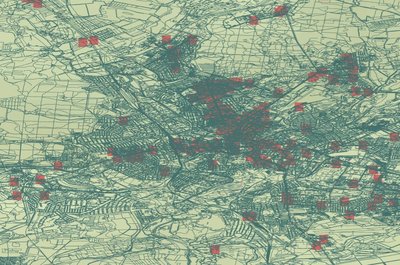
mk30 has been working on mixmap-georender, a component for rendering results from the database in webgl.
We don't have the data for planet.osm finished yet, but here is some of the progress so far with some test data:
rhodey has been making progress on the next version of swarmhead using docker and cabal, a p2p chat network based on many of the same dat project components we're using for peermaps.
swarmhead is a tool for coordinating many volunteer "drone machines" like seti@home or an irc bot net (but for non-nefarious purposes).
By building swarmhead on top of cabal, we can administer the peermaps cluster with the cabal clients that have already been developed, we can provide network status and transparency, and we can answer questions and resolve problems directly in the chat.
In addition to coordinating batch processing, swarmhead can also coordinate
"seed nodes" with a !seed command and a layer of curation provided in a
moderated cabal channel. The seed nodes decide among themselves how to best
share the work of seeding a set of archives that a single node might not even
have enough space to store by itself.
Speaking of cabal, substack worked on a rough outline for what p2p chat moderation could look like using materialized-group-auth.
We need to maintain a set of bots that have been vetted to participate into the network anyways, so rather than build this feature only for our own project, we built a reusable module and sent a pull request to cabal that we can use for swarmhead.
We've released a new rank+select database called bitfield-db for building peermq, a component of the OSM parallel batch processing system we're working on.
bitfield-db is based on the Roaring paper and fenwick trees.
With bitfield-db you can insert, delete, and test for set membership of positive integers as well as search for predecessor (previous) and successor (next) members in the set. The Roaring paper sets up some good trade-offs between CPU processing overhead for encoding, decoding, searching, and storage size. With this kind of database, we're building a p2p message queue that tracks which messages have been read or unread.
This is our first project licensed as license zero parity, a new copyleft license designed to be easy to understand and compatible with other "open" projects. We're looking into using this license to support our work on peermaps by selling copyleft exceptions, but for now it's simply a nice copyleft license designed for how open source works in practice right now.
In our batch processing cluster, we are using hypercore and the dat networking stack. This gives us some nice features out of the box such as a high tolerance to network partitions and temporary outages. But we needed to know when a message is successfully sent to a storage peer so we can delete it on the sending node to save space (planet.osm is 35+GB compressed and one of our goals is to use existing computers with perhaps only 5 or 10 GB to spare).
substack picked up from some previous work by emilbayes to implement acknowledgements in the hypercore protocol:
Another component we've developed for batch processing is random-access-osm-pbf, which lets us slice up the very large planet.osm file into more manageable chunks by scanning for alignment boundaries. This way we can use machines that don't individually have enough storage to save the whole file, but can still contribute to the batch processing task.
Thank you everyone who has contributed to our opencollective.
Hopefully you are satisfied by this report that the money has been put to good use.